
Boost Like a (Var)Pro: How Little Neural Networks Can Achieve Big Performance
ICERM - June 2026
by Abhijit Chowdhary (Tufts University), Elizabeth Newman (Tufts University), and Deepanshu Verma (Clemson University)
The wealth of available data and the rapid advancement and accessibility of computational tools has enabled deep learning to tackle some of the most complex scientific challenges of the day. In order to handle the complexity of such problems, the learned data-driven models have, by design, become massive. Training these models, posed as a high-dimensional non-convex optimization problem, thereby requires significant computational resources. Our project tackles these training challenges by pairing lightweight, structured models with powerful structure-exploiting optimization.
The wealth of available data and the rapid advancement and accessibility of computational tools has enabled deep learning to tackle some of the most complex scientific challenges of the day. In order to handle the complexity of such problems, the learned data-driven models have, by design, become massive. Training these models, posed as a high-dimensional non-convex optimization problem, thereby requires significant computational resources. Our project tackles these training challenges by pairing lightweight, structured models with powerful structure-exploiting optimization.
We start by phrasing the training problem abstractly in infinite-dimensional function space with a goal to minimize a loss functional \(\mathcal{L}\) via an additive ensemble, \(f = \sum_{j=1}^M f_j\). where each \(f_j\) is a lightweight model called a weak learner. We can then construct this ensemble greedily using a tried-and-true function space optimization algorithm: gradient boosting. In our particular setting, gradient boosting constructs weak learner \(m+1\) by minimizing a quadratic approximation of the loss functional
\(\DeclareMathOperator*{\argmin}{\arg\min}\)
\(f_{m+1} = \argmin\limits_{h} \langle \nabla \mathcal{L}[f^{(m)}], h \rangle + \tfrac{1}{2}\langle h, \nabla^2 \mathcal{L}[f^{(m)}]h\rangle\)
where \(f^{(m)} := \sum_{j=1}^m f_j\) is the ensemble containing the previous \(m\)weak learners.
A common technique to (approximately) solve the infinite-dimensional quadratic optimization problem is to first parameterize each weak learner. We then can optimize the finite-dimensional parameters using computationally-tractable algorithms. To encode regularity and accelerate optimization, we parameterize our weak learners as separable neural networks. This means that we assume each weak learner consists of a smooth nonlinear featurizer parameterized by \(\theta \in \mathbb{R}^{n_\theta}\) and a final linear mapping parameterized by w \(\in \mathbb{R}^{n_w}\); that is, \(\mathcal{h}\)(x) = \(A_{\theta}\)(x)w.
The separable structure merges seamlessly with the quadratic objective functional. In particular, we are able to analytically determine the optimal linear mapping for the given nonlinear weights, w\(_{\star}(\theta)\). The process of eliminating w by partial optimization is known as variable projection (VarPro) and can be shown to provably improve the optimization landscape and accelerate training.
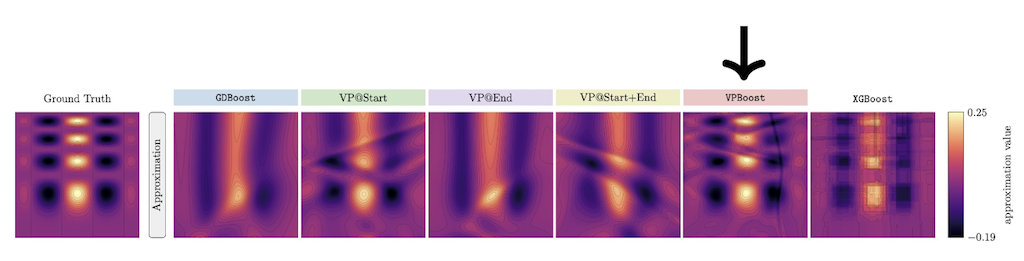
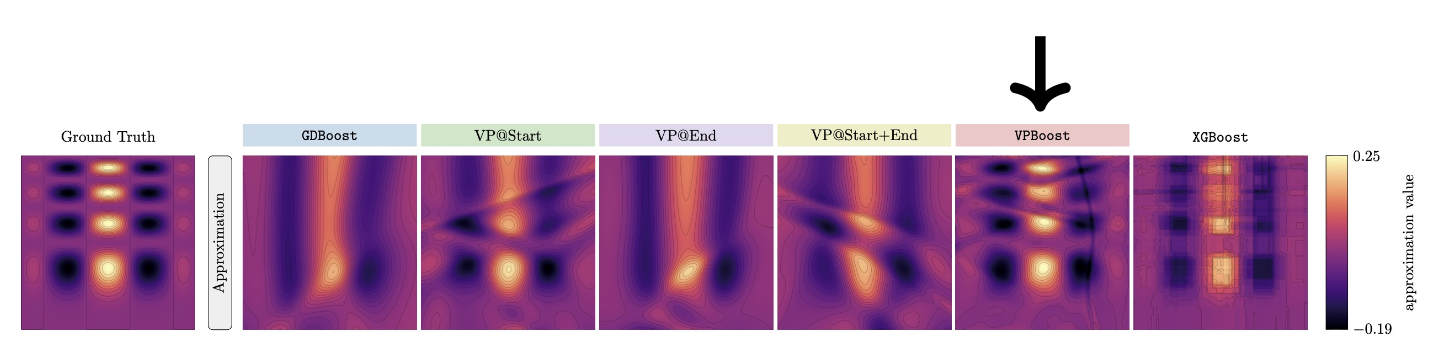
To recap, our method combines gradient boosting in function space, separable neural network parameterization of weak learners, and VarPro for improved parameter optimization. Hence, we call our new algorithm VPBoost: Variable Projection Gradient Boosting. As demonstrated in Figure 1, VPBoost can achieve more accurate function approximations efficiently with lightweight learners (few neural network weights) and fast, reliable optimization with VarPro.
Being semester-long participants at ICERM as part of “Stochastic and Randomized Algorithms in Scientific Computing: Foundations and Applications” program and having access to Brown University’s high performance computing cluster provided us with invaluable research support and a stimulating intellectual environment. These ingredients inspired us to push our research deeper into new theoretical and computational realms. The depth and quality of this work would not have been possible without this support.
For more details, please see our arXiv preprint Boost Like a (Var)Pro: Trust-Region Gradient Boosting via Variable Projection.
This material is based upon work supported by the National Science Foundation under Grant No. DMS-2424556 while the author was in residence at the Institute for Computational and Experimental Research in Mathematics in Providence, RI, during the Stochastic and Randomized Algorithms in Scientific Computing: Foundations and Applications program.